
The series so far:
- SQL Server Machine Learning Services – Part 1: Python Basics
- SQL Server Machine Learning Services – Part 2: Python Data Frames
- SQL Server Machine Learning Services – Part 3: Plotting Data with Python
- SQL Server Machine Learning Services – Part 4: Finding Data Anomalies with Python
- SQL Server Machine Learning Services – Part 5: Generating multiple plots in Python
- SQL Server Machine Learning Services – Part 6: Merging Data Frames in Python
With the release of SQL Server 2017, Microsoft changed the name of R Services to Machine Learning Services (MLS) and added support for Python, a widely implemented programming language known for its straightforward syntax and code readability. As with the R language, you can use Python to transform and analyze data within the context of a SQL Server database and then return the modified data to a calling application.
In this article, I explain how to run Python scripts within SQL Server. I start by introducing the sp_execute_external_script stored procedure and then dive into specifics about working with Python scripts. If you’re familiar with running R scripts in SQL Server, you already have the foundation you need to get started with Python. You use the same stored procedure and its parameters, merely swapping out one programming language for the other. The differences between the two approaches are primarily within the languages themselves.
This article is the first in a series about MLS and Python. In it, we’ll review several examples that demonstrate how to run Python scripts, using data from the AdventureWorks2017 database. The examples are very basic and meant only to introduce you to the fundamentals of working with Python in SQL Server. In subsequent articles, we’ll dig into Python’s capabilities in more depth, relying on this article as a foundation for the ones to follow.
Getting started with Python scripting
To run a Python script in SQL Server, use the sp_execute_external_script stored procedure. First you must ensure that the database engine’s MLS and Python components are installed, and the external scripting feature is enabled. For details on how to get all this set up, see the Microsoft document Set up Python Machine Learning Services (In-Database).
After MLS has been installed and enabled, you can use the sp_execute_external_script stored procedure to run Python scripts (or R scripts, for that matter). The following syntax shows the procedure’s basic elements:
|
1 2 3 4 5 6 7 8 9 10 |
sp_execute_external_script @language = N'language', @script = N'script' [,] [ @input_data_1 = 'SelectStatement' [,] ] [ @input_data_1_name = N'InputDataVariable' [,] ] [ @output_data_1_name = N'OutputDataVariable' [,] ] [ @params = N'@ParamName DataType [ OUT | OUTPUT ] [ ,...n ]' [,] ] [ @ParamName = 'value' [ OUT | OUTPUT ] [ ,...n ] ] [ WITH RESULT SETS { UNDEFINED | NONE | (( OutputColumnName [,...n ] )) } ] [;] |
You’ll learn the specifics of the syntax as you work through the examples in this article. Note, however, that the SQL Server document sp_execute_external_script (Transact-SQL) no longer includes the WITH RESULTS SETS clause as part of the syntax as it has in the past. Instead, the document points to the EXECUTE (Transact-SQL) topic for details on how to use this clause. I’ve included it here for completeness, but it’s actually part of the EXECUTE command.
To demonstrate how to run the sp_execute_external_script stored procedure, start with a simple example that retrieves sales data from the AdventureWorks2017 database, passes the data into a Python script, and then returns the data without modifying it:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
Use AdventureWorks2017; GO -- define Python script DECLARE @pscript NVARCHAR(MAX); SET @pscript = N' # assign SQL Server dataset to df variable df = InputDataSet # return df dataset OutputDataSet = df'; -- define T-SQL query DECLARE @sqlscript NVARCHAR(MAX); SET @sqlscript = N' SELECT t.Name AS Territories, CAST(h.Subtotal AS FLOAT) AS Sales FROM Sales.SalesOrderHeader h INNER JOIN Sales.SalesTerritory t ON h.TerritoryID = t.TerritoryID;'; -- run procedure, using Python script and T-SQL query EXEC sp_execute_external_script @language = N'Python', @script = @pscript, @input_data_1 = @sqlscript; GO |
The example can be broken into three distinct steps:
- Declare the @pscript variable, define the Python script, and assign the script to the variable.
- Declare the @sqlscript variable, define the T-SQL query, and assign the query to the variable.
- Run the sp_execute_external_script stored procedure, passing in the @pscript and @sqlscript variables. You don’t have to pass the Python script and T-SQL query as variables, but it makes the code more readable.
Begin with the first step. After declaring the @pscript variable, you create the Python script, which starts by assigning the output from the T-SQL query to the df variable:
|
1 |
df = InputDataSet |
By default, the data returned by the T-SQL query can be accessed within the Python script by calling the InputDataSet variable. In this way, you can assign the SQL Server dataset to the df variable and then work with that dataset as necessary. As you’ll see later in the article, you can also specify another name to replace the InputDataSet variable, but for now, stick with the default.
Next, assign the df dataset to the OutputDataSet variable:
|
1 |
OutputDataSet = df |
The OutputDataSet variable is the default variable used to return the script’s data to the calling application. As with the InputDataSet variable, you can change the name, but for now, use the default.
In this case, the script does nothing more than return the same data that you’re retrieving from SQL Server, something you could have done without using a Python script. In fact, you do not even have to include the df variable and can instead simply assign the input variable to the output variable:
|
1 |
OutputDataSet = InputDataSet |
I’ve included the df variable here to help demonstrate how to begin working with SQL Server data within a Python script. More often than not, you’ll want to manipulate and analyze the SQL Server data. Assigning the source data to a separate variable allows you to modify the source data, while still maintaining the original dataset. It’s up to you to decide the best way to move data from one object to the next, based on your specific circumstances.
Next, define the T-SQL query and assign it to the @sqlscript variable. In this case, the query is just a simple join, but you can make it as complex as it needs to be. One item worth noting, however, is that the code converts the Sales column to the FLOAT data type. This is because Python supports a limited number of types when compared to SQL Server, and the Python engine can implicitly convert only some of the SQL Server types.
For example, the Territories column is configured with the NVARCHAR data type. When the Python script runs, the Python engine implicitly converts the column to the Python str type. However, the Sales column is configured with the MONEY type. The Python engine cannot implicitly convert this type, so you must explicitly convert it to one that the engine can handle. In this case, you’re converting the Sales column to FLOAT, which the Python engine can then convert to the Python float64 type. (For more information on the SQL Server types that Python supports, see the Microsoft document Python Libraries and Data Types.)
After defining the Python script and T-SQL query, you can call the sp_execute_external_script stored procedure, passing in the necessary parameter values. For the @language parameter, specify Python. If you were working with an R script, you would pass in R as the value. Currently, those are the only two values that the parameter supports.
For the @script parameter, specify the @pscript variable, and for the @input_data_1 parameter, specify the @sqlscript variable. The @input_data_1 parameter is optional. You do not have to include SQL Server data in the Python script, but if you’re going to be running Python within the SQL Server environment, it seems likely you’ll want to use SQL Server data.
With the parameters in place, you can call the stored procedure. When you do, the Python engine runs the Python script, using the SQL Server data, and returns the dataset to the calling application. The following figure shows the first chunk of rows returned by the script.
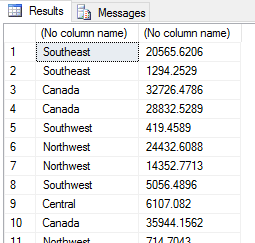
As you can see, the Python script returns a basic result set with the data organized into columns and rows, just like the source data. You might have noticed, however, that the returned data includes no column names. For that, you need to specifically assign names to the returned data.
Assigning names to Python script objects
When using the sp_execute_external_script stored procedure to run Python scripts, you can specify names for the default variables assigned to the input and output datasets. You can also specify column names for the outputted dataset. The following procedure call assigns the name RawData to the input variable, the name SumData to the output variable, and the names Territories and Sales to the output columns:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
DECLARE @pscript NVARCHAR(MAX); SET @pscript = N' # assign SQL Server dataset to df df = RawData # return df dataset SumData = df'; DECLARE @sqlscript NVARCHAR(MAX); SET @sqlscript = N' SELECT t.Name AS Territories, CAST(h.Subtotal AS FLOAT) AS Sales FROM Sales.SalesOrderHeader h INNER JOIN Sales.SalesTerritory t ON h.TerritoryID = t.TerritoryID;'; EXEC sp_execute_external_script @language = N'Python', @script = @pscript, @input_data_1 = @sqlscript, @input_data_1_name = N'RawData', --input variable name @output_data_1_name = N'SumData' --output variable name WITH RESULT SETS( (Territories NVARCHAR(50), Sales MONEY)); --output column names GO |
To rename the input variable, you must include the @input_data_1_name parameter when calling the sp_execute_external_script stored procedure, assigning the new name to that parameter. You must then use the name within the Python script when referencing the input dataset:
|
1 |
df = RawData |
To rename the output variable, you must include the @output_data_1_name parameter when calling the stored procedure, assigning the new name to that parameter. You must then use that name within the Python script when referencing the output dataset:
|
1 |
SumData = df |
The next step is to assign names to the columns. To do this, include the WITH RESULT SETS clause when calling the stored procedure, specifying the column names and their data types. The list of column names must be enclosed in double parentheses with the names separated by commas. SQL Server will then assign those names to the output dataset in the order they’re specified, as shown in the following results.
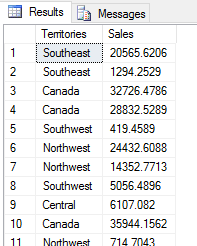
When assigning column names, keep in mind that the database engine must be able to implicitly convert the returned data to that type. For example, in the WITH RESULT SETS clause above, you assign the Territories name to the first column, specifying the NVARCHAR(50) data type. If you had instead specified CHAR(5), many of the column values would have been truncated. If you had specified INT for Sales, the database engine would have returned an error.
With regard to the Sales column, SQL Server easily converts the Python float64 type to the SQL Server MONEY type without changing the data. You can get away with this because the values are already limited to four decimal places when you import the data into the Python script. If there had been a greater number of decimal places in the data returned by the Python script, the values would have been rounded when they were converted. Often this will not be a problem, depending on the level of precision that’s required, but it points to the fact that, whenever data is implicitly converted, you need to be aware of its potential impact.
When it comes to the output dataset, it’s up to you whether to specify column names. You’ll likely want to decide on a case-by-case basis, depending on your application needs.
The same goes for renaming the input and output variables. There might be times when renaming them can be useful for clarity, especially if you’re importing additional datasets. Often, however, it’s just a matter of preference. Personally, I prefer not to rename the input and output variables if there’s no overriding reason to do so. I find it easier to review code that uses the default names.
Manipulating the Python data frame
If you’ve worked with the R language in SQL Server, you’re no doubt familiar with the concept of the data frame, a two-dimensional data structure similar to a SQL Server table. Data frames make it easier to manipulate and analyze sets of data within your scripts. Python data frames operate much the same way as they do in the R language and are essential to working with the data within the context of SQL Server.
The InputDataSet and OutputDataSet variables both store data as data frames. This is true even if you rename the variables. The variables are both DataFrame objects, based on the DataFrame class. The SQL Server data imported into a Python script is converted to a DataFrame object, and the data returned by a Python script is passed to the output variable as a DataFrame object. And much of what you do with that data in between often involves DataFrame objects.
A simple way to confirm that you’re working with data frames is to modify the first example to return only the data type of the df variable:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
DECLARE @pscript NVARCHAR(MAX); SET @pscript = N' # assign SQL Server dataset to df df = InputDataSet # retrieve type of df object print(type(df))'; DECLARE @sqlscript NVARCHAR(MAX); SET @sqlscript = N' SELECT t.Name AS Territories, CAST(h.Subtotal AS FLOAT) AS Sales FROM Sales.SalesOrderHeader h INNER JOIN Sales.SalesTerritory t ON h.TerritoryID = t.TerritoryID;'; EXEC sp_execute_external_script @language = N'Python', @script = @pscript, @input_data_1 = @sqlscript; GO |
To get the data type, you call the type function, specifying the df variable, and then call the print function to return the data type to the application. When I ran this script in SQL Server Management Studio, I received the following message:
|
1 2 |
STDOUT message(s) from external script: <class 'pandas.core.frame.DataFrame'> |
As you can see, the df variable is a DataFrame object, which it inherited from the InputDataSet variable. Notice, however, that the namespace is actually pandas.core.frame.DataFrame. This is because the DataFrame class is part of the Pandas library which is included in the MLS Python installation. We’ll be covering the Pandas library in more detail in subsequent articles. Until then, you can learn more about Pandas at https://pandas.pydata.org/.
Now try to do something with the data you’re importing from SQL Server. You’ll start by aggregating the Sales values to determine the total amount of sales per territory:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
DECLARE @pscript NVARCHAR(MAX); SET @pscript = N' # calculate sales totals for each territory df1 = InputDataSet df2 = df1.groupby("Territories", as_index=False).sum() # return aggregated dataset OutputDataSet = df2'; DECLARE @sqlscript NVARCHAR(MAX); SET @sqlscript = N' SELECT t.Name AS Territories, CAST(h.Subtotal AS FLOAT) AS Sales FROM Sales.SalesOrderHeader h INNER JOIN Sales.SalesTerritory t ON h.TerritoryID = t.TerritoryID;'; EXEC sp_execute_external_script @language = N'Python', @script = @pscript, @input_data_1 = @sqlscript WITH RESULT SETS( (Territories NVARCHAR(50), TotalSales MONEY)); GO |
To aggregate the data in the df1 data frame, call the object’s groupby function which is a member of the Pandas DataFrame class:
|
1 |
df2 = df1.groupby("Territories", as_index=False).sum() |
When calling the groupby function, specify the df1 variable, followed by a period and then the function name. Although the function can take several arguments, this example includes only two. The first is the Territories column which indicates that the data will be grouped based on values in that column. The second argument is the as_index option which is set to False. This tells the Python engine to return the Territories values, ensuring that the unique Territories names are included in the results along with the aggregated sales data.
After specifying the groupby arguments, tag on the sum function to indicate that the Sales values should be added together for each group. You can use any of the supported aggregate functions, such as mean, max, min, first, or last.
Because the Sales column is the only column in the dataset other than Territories, you do not need to do anything else with the function itself. Had the dataset contained additional columns that you did not want to include, you would have had to specify the Sales column when calling the groupby function.
Next, assign the aggregated results to the df2 variable and then assign that variable to the OutputDataSet variable, giving the following results.
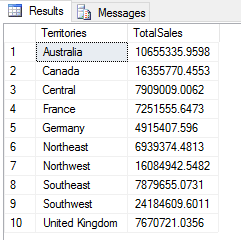
The next step is to add a calculated column to the df2 data frame that rates a territory’s performance based on the aggregated Sales values. To do so, modify the data frame by defining the range of each predefined value:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
DECLARE @pscript NVARCHAR(MAX); SET @pscript = N' # calculate sales totals for each territory df1 = InputDataSet df2 = df1.groupby("Territories", as_index=False).sum() # add Performance column df2["Performance"] = "Acceptable" df2["Performance"][df2["Sales"] < 7000000] = "Poor" df2["Performance"][df2["Sales"] > 10000000] = "Excellent" # return aggregated dataset OutputDataSet = df2'; DECLARE @sqlscript NVARCHAR(MAX); SET @sqlscript = N' SELECT t.Name AS Territories, CAST(h.Subtotal AS FLOAT) AS Sales FROM Sales.SalesOrderHeader h INNER JOIN Sales.SalesTerritory t ON h.TerritoryID = t.TerritoryID;'; EXEC sp_execute_external_script @language = N'Python', @script = @pscript, @input_data_1 = @sqlscript WITH RESULT SETS( (Territories NVARCHAR(50), TotalSales MONEY, Performance NVARCHAR(20))); GO |
Start by defining a new column named Performance and assigning the default value Acceptable to the column:
|
1 |
df2["Performance"] = "Acceptable" |
To add the column, you need only specify the df2 variable, followed by brackets that include the name of the new column in quotes. You then use an equal operator (=) to set the column’s default value to Acceptable.
Next, modify the column definition to include a second possible value, using a conditional expression to define a data range for when to apply that value:
|
1 |
df2["Performance"][df2["Sales"] < 7000000] = "Poor" |
Again, start by specifying the df2 variable and the name of the column in brackets. Next, define the conditional expression, enclosed in a second set of brackets. The expression states that if the Sales value is less than 7 million, the Performance value should be set to Poor. You then repeat this process to add a third value, only this time the conditional expression indicates that, if the Sales value exceeds 10 million, the Performance value should be set to Excellent:
|
1 |
df2["Performance"][df2["Sales"] > 10000000] = "Excellent" |
That’s all there is to adding a calculated column to the data frame. The Python script now returns the results shown in the following figure.
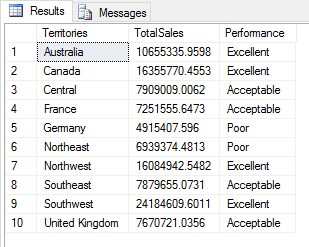
Of course, you could have achieved the same results with T-SQL alone, but even such a simple example helps demonstrate some of the ways that you can manipulate data to achieve various results. In practice, your Python scripts will likely be much more complex if you are to perform meaningful analytics.
Running a Python script within a stored procedure
Often when you’re working with Python, you’ll want to call the sp_execute_external_script stored procedure from within a user-defined stored procedure that can then be evoked from a calling application. To do so, simply embed the T-SQL and Python code and sp_execute_external_script procedure call in the procedure definition, as shown in the following example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
DROP PROCEDURE IF EXISTS dbo.GetSalesTotals; GO CREATE PROCEDURE dbo.GetSalesTotals AS SET NOCOUNT ON; DECLARE @pscript NVARCHAR(MAX); SET @pscript = N' # calculate sales totals for each territory df1 = InputDataSet df2 = df1.groupby("Territories", as_index=False).sum() # add Performance column df2["Performance"] = "Acceptable" df2["Performance"][df2["Sales"] < 7000000] = "Poor" df2["Performance"][df2["Sales"] > 10000000] = "Excellent" # return aggregated dataset OutputDataSet = df2'; DECLARE @sqlscript NVARCHAR(MAX); SET @sqlscript = N' SELECT t.Name AS Territories, CAST(h.Subtotal AS FLOAT) AS Sales FROM Sales.SalesOrderHeader h INNER JOIN Sales.SalesTerritory t ON h.TerritoryID = t.TerritoryID;'; EXEC sp_execute_external_script @language = N'Python', @script = @pscript, @input_data_1 = @sqlscript WITH RESULT SETS( (Territories NVARCHAR(50), TotalSales MONEY, Performance NVARCHAR(20))); GO |
There’s no magic here, just a basic definition that creates the GetSalesTotals procedure which calls the sp_execute_external_script procedure and passes in the Python script and T-SQL query as we’ve seen in previous examples. You can then use an EXECUTE statement to run the procedure:
|
1 |
EXEC dbo.GetSalesTotals; |
The procedure will return the same results as the previous example, only now you’re able to persist the logic. You can also define a stored procedure to include input parameters whose values can then be consumed by the Python script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
DROP PROCEDURE IF EXISTS dbo.GetSalesTotals; GO CREATE PROCEDURE dbo.GetSalesTotals (@low INT, @high INT) --add procedure parameters AS SET NOCOUNT ON; DECLARE @pscript NVARCHAR(MAX); SET @pscript = N' # calculate sales totals for each territory df1 = InputDataSet df2 = df1.groupby("Territories", as_index=False).sum() # add Performance column df2["Performance "] = "Acceptable" df2["Performance "][df2["Sales"] < LowSales] = "Poor" df2["Performance "][df2["Sales"] > HighSales] = "Excellent" # return aggregated dataset OutputDataSet = df2'; DECLARE @sqlscript NVARCHAR(MAX); SET @sqlscript = N' SELECT t.Name AS Territories, CAST(h.Subtotal AS FLOAT) AS Sales FROM Sales.SalesOrderHeader h INNER JOIN Sales.SalesTerritory t ON h.TerritoryID = t.TerritoryID;'; EXEC sp_execute_external_script @language = N'Python', @script = @pscript, @input_data_1 = @sqlscript, @params = N'@LowSales FLOAT, @HighSales FLOAT', --define Python variables @LowSales = @low, --assign procedure parameter to Python variable @HighSales = @high --assign procedure parameter to Python variable WITH RESULT SETS( (Territories NVARCHAR(50), TotalSales MONEY, Ratings NVARCHAR(20))); GO |
This time, when defining the stored procedure, include two input parameters, @low and @high, both defined with the INT data type. The first parameter will set the low range for the calculated column, and the second parameter will set the high range.
You then need to tie these parameters to the Python script. To do so, include three additional parameters when calling the sp_execute_external_script stored procedure. The first is the @params parameter, which specifies the @LowSales and @HighSales parameters. These are used to pass values into the Python script. Both parameters are defined with the FLOAT data type.
You must then assign the @low and @high parameters to the @LowSales and @HighSales parameters, respectively:
|
1 2 |
@LowSales = @low, @HighSales = @high |
You can then reference the @LowSales and @HighSales parameters inside the Python script using the names LowSales and HighSales:
|
1 2 |
df2["Ratings"][df2["Sales"] < LowSales] = "Poor" df2["Ratings"][df2["Sales"] > HighSales] = "Excellent" |
Now when you call the stored procedure, you can pass in the low and high values used to define the ranges in the Performance column:
|
1 |
EXEC dbo.GetSalesTotals @low = 7000000, @high = 10000000; |
In this case, you’re specifying the same values that you used in the previous example, so you will receive that same results. However, you can also specify different values:
|
1 |
EXEC dbo.GetSalesTotals @low = 5000000, @high = 20000000; |
The stored procedure now returns the results shown in the following figure which indicate that only one territory is performing poorly and only one above average.
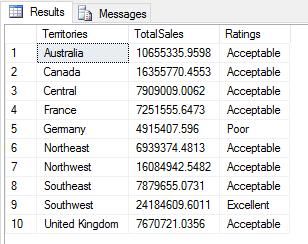
Although this is a fairly trivial example, it demonstrates how you can dynamically interact with the Python script by passing in values when calling stored procedures in order to better control the results.
Getting to know Python and Machine Learning Services
Clearly, we’ve barely skimmed the surface of all we can do with Python in SQL Server. Python is a flexible and extensive language that provides a wide range of options for manipulating and analyzing data. Best of all, being able to run Python within SQL Server makes it possible to analyze a database’s data directly within the context of that database.
As we progress through this series, we’ll dig more into the Python language and the various ways we can use it to manipulate data and perform analytics. In the meantime, this article should provide you with a good foundation for getting started with Python in SQL Server. We’ll be building on this foundation going forward. I also encourage you to dig into Python yourself and play with it in the context of SQL Server. The better you understand that language, the more powerful a tool you’ll have for working with SQL Server data.



Load comments